The Game-Changing AWS Bedrock Converse API: Why You Should Care
On May 30, 2024, AWS did something amazing.
They released the AWS Bedrock Converse API. If you don't know why this is such a big deal, please read on.
Before the Converse API was released, switching between AI models required a lot of effort. A sizable chunk of code had to be rewritten. This made trying out different more cheaper models harder to do. Not as easy as turning off an EC2 instance and swapping the instance type, no. Code changes. Integration code, probably unit tests, integration tests, end to end tests. I've read online of references about teams writing entire wrapper libraries to abstract away the differences, but I would imagine most companies out there didn't do all this, they wrote integration code for one model, and when they changed the model to another and saw that everything broke, they just swapped it back, maybe backlogged some story to do the work, and maybe they get around to it, maybe not.
This has impacts. What if you went for the most expensive model first to ensure your idea worked? You're paying the price for that model's usage until you can change the code. It's not a great situation to be in.
AWS recognized this burden, saw that it was slowing teams down needlessly. So they responded by creating the AWS Bedrock Converse API. As AWS stated in their announcement:
The Converse API provides a consistent experience that works with Amazon Bedrock models, removing the need for developers to manage any model-specific implementation. With this API, you can write a code once and use it seamlessly with different models on Amazon Bedrock.
You can read the full announcement here: https://aws.amazon.com/about-aws/whats-new/2024/05/amazon-bedrock-new-converse-api/
The converse API provides a uniform API for accessing all AWS Bedrock models the exact same way. It's huge. With this, now you don't need to change code to swap models. Simply swap models, and move on. With a 1 line code change (if that, haven't you paramaterized that?) you can use a different model.
The impact? Easy transitions to new models, and everything just works. Though for some reason, a lot of people unfamiliar with AWS Bedrock don't know about the converse API and how easy it is to switch between models when you go Converse API first. AI engineers can test and rapidly inovate with new models. Also reducing technical debt, and future-proofing for the forseeable future. I would imagine if any new LLM features were introduced in AWS Bedrock, AWS Would do their best to make it uniform via the Converse API.
I've actually already blogged about overcoming more complex challenges using cross-regional inference in AWS via the Converse API WITH tool usage, detailed here: https://wayne.theworkmans.us/posts/2025/08/2025-08-23-parsing-bedrock-converse-api-responses.html
But I felt the need to take it back to basics and spread the good word that YES, you can 100% change models in AWS Bedrock trivially if you're using the converse API. And if you're not using the Converse API, it's a lot harder.
Also some side notes (these are AWS best practices explicitly from their docs):
- Converse API is now the preferred and recommended approach
- Use Converse API for all new projects, conversational applications, multi-turn dialogs, and tool use.
- Use Invoke API only for embedding models, image generateion, or specific legacy requirements.
If you're curious what all is involved to go from the Invoke API to the Converse API for a serious project, I've been through it. You can go look at this commit here. While this commit did a lot more than just swapping over from the invoke API to the Converse API, it gives you an idea of what's involved.
https://github.com/wayneworkman/terraform-aws-module-cloudwatch-alarm-triage/commit/022ce12e811282300a1c6ce30949d750c459772d
Real World Examples
So after work today I decided to create some distilled examples to really show the stark difference, I spent my personal time on my personal laptop using my personal AWS accounts and my personal money to create these examples because I think it's that important for people to understand this difference and I want more folks to adopt the Converse API.
Here's some commits showing the very stark contrast between changing models when using the invoke API versus changing models when using the converse API.
First, let's look at what happens when you need to change models using the traditional Invoke API:
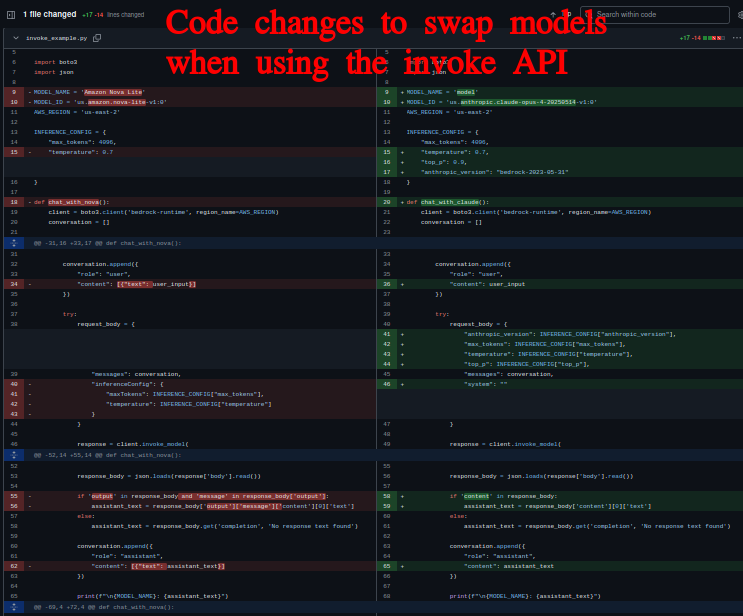
Invoke API model change commit: https://github.com/wayneworkman/python_aws_bedrock_converse_example/commit/04f507034dd847e4a894298c784b838b1765053e
Look at all that red and green. That's a lot of code that had to change just to swap from Nova Lite to Claude. Different parameter names, different response structures, different everything. This is what teams have been dealing with.
Now, let's look at the exact same model change but using the Converse API:
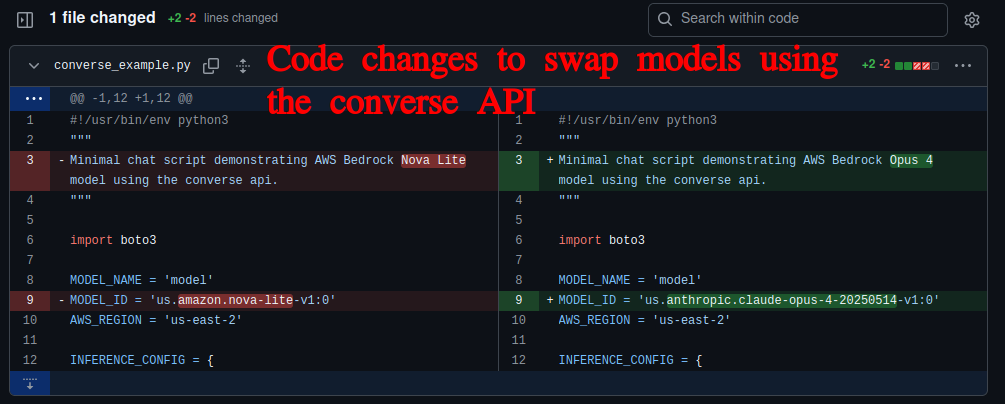
Converse API model change commit: https://github.com/wayneworkman/python_aws_bedrock_converse_example/commit/fe8bd90f9f2a6d920ee60bed3baf1ae0a9f01749
Pretty crazy, huh? Literally just changing the model ID. That's it. Everything else stays exactly the same.
Turns out, the converse API allows for model changes without changing code, and everything still works! The only question with changing models via the converse API is if the model you're swapping to is capable enough or not. It's not a question of changing code, but rather a question of selecting the cheapest model that is still able to complete the task at hand.
And remember, using the Converse API is now the AWS recommended best practice. There's literally no reason not to use it for new projects. Your future self (and your team) will thank you.