When Bad Shuffling Breaks Training: A Home Lab Lesson
This is a personal project I've been working on in my home lab during my free time, completely seperate from my day job.
I've been obsessed with a specific question lately: Can I train a Small Language Model from scratch that actually knows someting about World War II? Not just generic Wikipedia recitation, but genuine reasoning and recall.
I'm not talking about fine-tuning Llama 3. I mean starting from torch.init() with random weights, building a dataset, and training the whole thing myself.
The Dataset Problem
I started with 301 Wikipedia articles about WWII. That's a good foundation but not enough to make a model that can reason through complex questions so I spent about 3 months using Alibaba Cloud's Qwen 2.5 7B Instruct to generate synthetic training data.
I created two types of QA pairs. "Open Book" questions where the model sees the source text and has to extract or reason about it. And "Closed Book" questions where the model has to pull from memory. I doubled the dataset size, simulated RAG contexts, varied the verbosity, basically every trick I could think of to make the data diverse enough that the model wouldn't just memorize patterns.
So far I've generated 297,575,475 tokens of high-quality, dense training data (using my customized 8k SentencePiece tokenizer vocabulary) from just those 301 Wikipedia articles, which felt like a solid foundation for a nano-sized model.
Enter the Hardware Problem
I spun up a fresh 54 million parameter model (a "nano" architecture that should be Chinchilla-optimal for this dataset size) and hit train.
Then I hit a wall. My computer only has 32GB of RAM and trying to load nearly 300 million tokens and their associated metadata into memory for a proper global shuffle was completley impossible, the system consumed all available RAM and went completely unresponsive which forced me to do my first ungraceful shutdown since I built my new full-size tower with my NVIDIA RTX 4070 Ti Super.
The "Good Enough" Shuffle
In every Deep Learning 101 course you learn that your data must be shuffled otherwise the model overfits on whatever topic it sees first and forgets everything else, but I couldn't do a global shuffle because of the RAM constraints so I wrote a compromise script that read chunks of data, shuffled them locally, and saved them back to disk.
I figured it was "good enough." Spoiler: it wasn't.
The Graph I Couldn't Stop Watching
I started the training run before work. At lunch I checked the logs and my customized loss graph and realized something was going wrong so I started working on a fix but ran out of time and had to get back to work. The process just kept running with the poorly shuffled data for another 8 hours, through the rest of my shift, taking my kid to gymnastics after work, during dinner, all of it, because I just didn't have time to do anything about it until tonight.
When I finally got back to it the loss graph was the most telling:
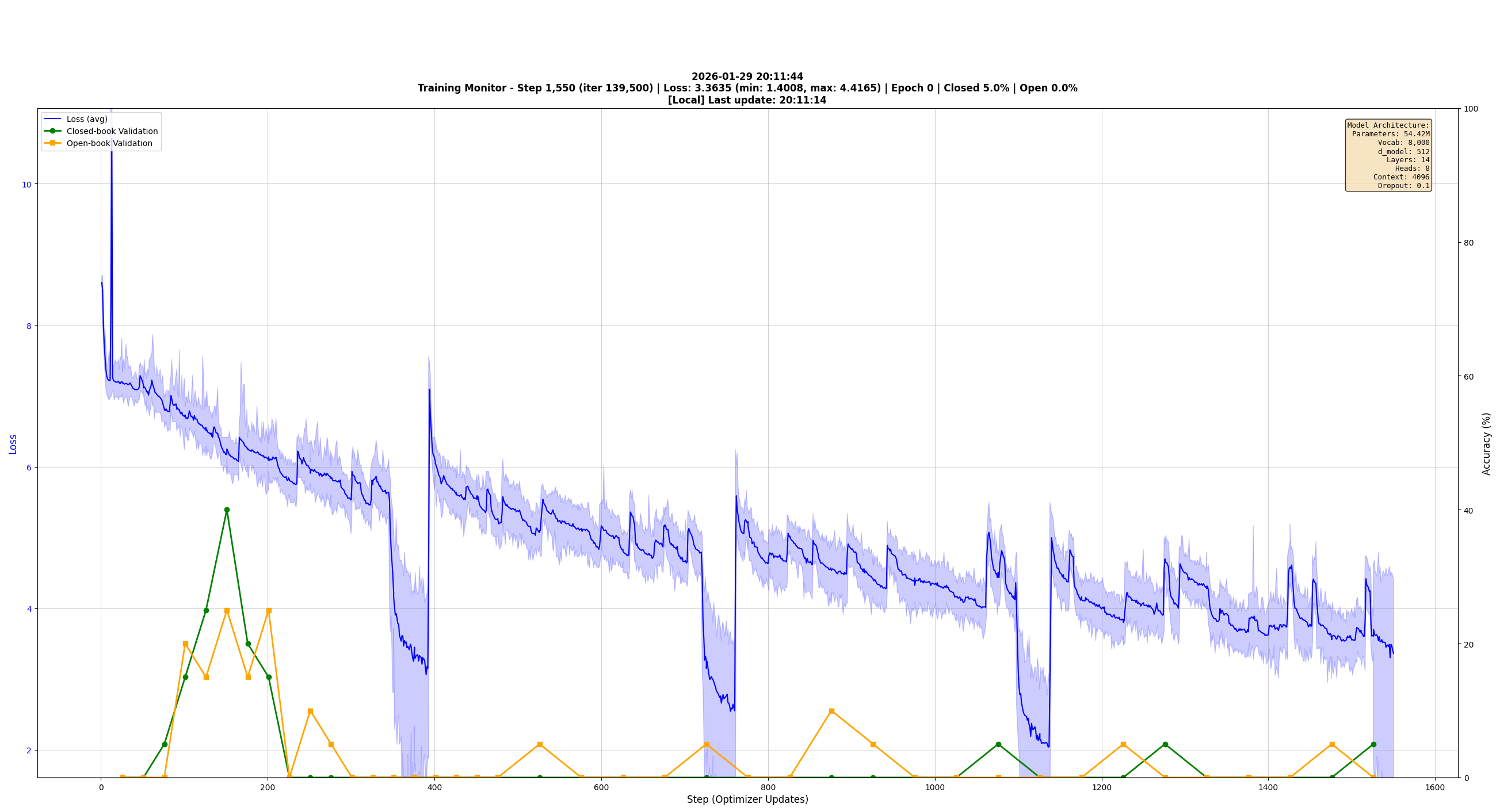
This graph is a textbook example of Data Clumping. If you look at the blue line (training loss) you see a distinct sawtooth pattern. The loss drops as the model over-trains on one topic, then spikes back up when the topic changes and it encounters new knowledge, then drops again, repeating over and over. The model never really learned anything, it just got good at swapping output patterns and key terms.
What Was Actually Happening
Because my "good enough" shuffle wasn't global the model was reading files that were effectively sorted by topic and it was cramming like a college student the night before an exam.
- Hours 0-2: The model sees only Eastern Front data. It learns "Soviet," "Winter," "Tanks." Loss goes down.
- Hour 3: The file changes to Pacific Theater. Now its "Carriers," "Marines," "Ocean." The model's weights are tuned for snow and tanks so the loss spikes violently.
The smoking gun is the green line (validation accuracy) which hit 58% early on then crashed to near 0% and stayed there, the model wasn't learning history it was becoming a quick-change artist rewriting its entire brain every time the topic shifted which is basically useless for any real application.
The Fix: Old School Data Engineering
I could've thrown more RAM at the problem (my board supports it) but 32GB is plenty if you use it wisely and RAM is really expensive right now thanks to the AI boom, so I had to solve it with algorithms and the solution turned out to be a technique as old as MapReduce: The Sharded Shuffle.
It works in two phases.
Phase 1: The Scatter
Instead of reading the entire file into memory I stream it line-by-line and for every line I assign it to one of 1000 temporary shard files at random.
- Input: An ordered list (Stalingrad → Midway → D-Day)
- Output: 1000 files where D-Day facts sit next to Stalingrad facts
- RAM Usage: Near zero
Phase 2: The Gather
I read each shard back one at a time and write it to the final dataset. Since each shard contained only about 1,000 JSONL lines it fits easily in RAM.
The result is a globally shuffled dataset that never required more than a few MB of RAM at any given time. The random assignment to shards in Phase 1 was all the shuffling needed.
Lessons Learned
In the era of 128GB A100 nodes its easy to forget the engineering constraints that defined early computing but when you're running a home lab those constraints become the best teachers and honestly I think more people should experience them because they force you to think about efficiency in ways that unlimited cloud resources dont.
My sawtooth graph was a failure but a productive one. It proved that for Small Language Models data distribution matters more than data quality. You can have the best synthetic data in the world generated by the smartest models but if you feed it in the wrong order your student model wont learn a thing.
I just finished implementing the sharded shuffle technique and started the new training run a few minutes ago. The early loss curve looks smooth so far, no sawtooth pattern yet. And hopefully this time the model will actually remember who won the war.