Using the LLM last: Deterministic-first typography cleaning with inference as a fallback
I'm working on a new model I call Aspasia. Aspasia is an "old soul" that has a knowledge cutoff of 1930; the latest year of copyrighted written works that have entered into the public domain by virtue of age.
One of the more important items in the corpora is the Encyclopaedia Britannica from 1911. This is the famous 11th edition pulled from Wikisource. It has approximately 36,957 usable articles of dense beautifully written century old prose. Part of the challenge with the encyclopedia from Wikisource is getting clean data out of it to train on.
Kudos to Wikisource
Firstly, I want to give credit to Wikisource for the amazing work they have done. It's important work and valuable. Namely - seperating those articles out into their own pages. That's the main reason why I picked Wikisource, because Project Gutenberg doesn't separate out artices it's all in one big text file together.
The messy source
Choosing Wikisource came with it's own drawbacks. HTML and LaTeX and other cruft mixed into just about everything, everywhere. Especially tables, but we'll get to that later. Some of the issues I had to solve while downloading and parsing the articles:
- If you naively flatten the HTML like I did, it puts a newline or stray space at every inline-element boundary. so
<i>abba</i>, fathercomes out asabba , father. This was a real line from Abbey), and a subscripted variablef<sub>c</sub>came out asf c. - Figure references for images that aren't present. Sprinkled throughout most artiles there would be
Fig. 1,Fig. 2and(fig. 3)and other references. As well as captions for those figures. - Tables four different HTML encodings (more on this later).
- Inline mathimatical formulas with no MathML, except where there was some MathML, whose extraction was filled with raw LaTeX.
- Every bigger article had a bibliography at the end with contributor initials and cross references, fullwidth operators and no-break spaces, word joinings, this is all the long tail of human typography.
The most obvious approach is to throw the whole page at a capable open-weights model and tell it to return clean text. That's a waste, and a really expensive one, even for open-weights models. Because GPU time is precious. How I actually went about this ...
First rule - deterministic first, because it is exact and free
Most of the articles did have structure and you can write code to clean it up. The HTML flattening can be repaired by extracting block-by-block and repairing the known issues like pulling the space off of abba,, you can fold f _c back into f_c, you can map a full width equals symbol back to a standard equals symbol, drop zero-width invisibile junk characters. And after all that, use consistent space characters with a search and replace.
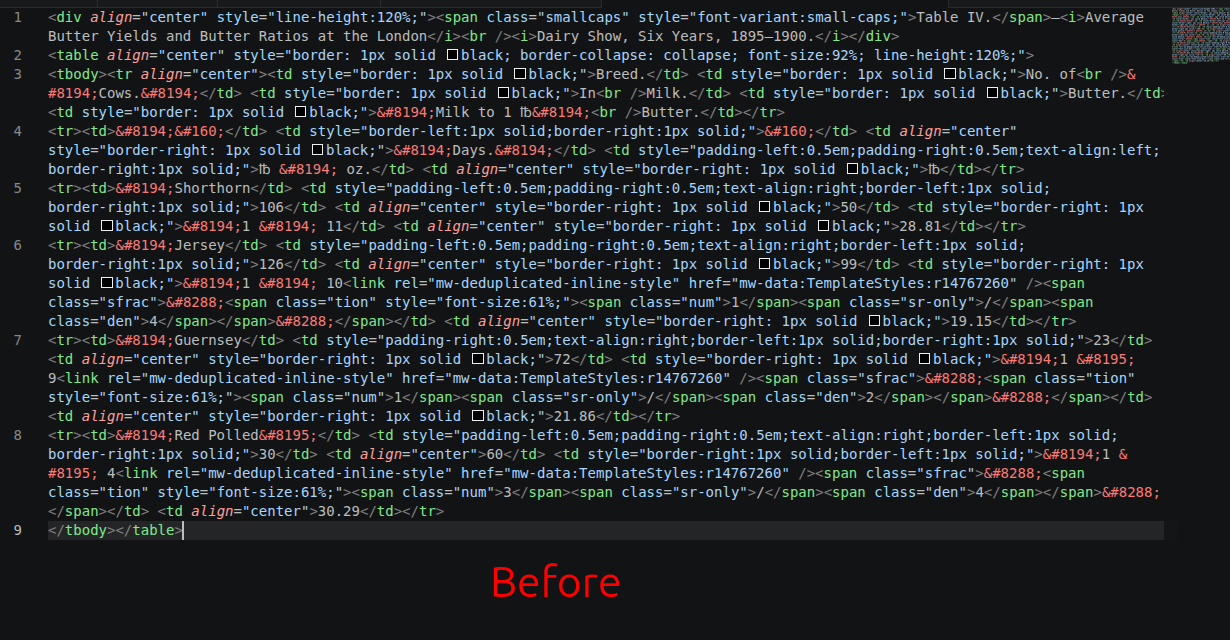
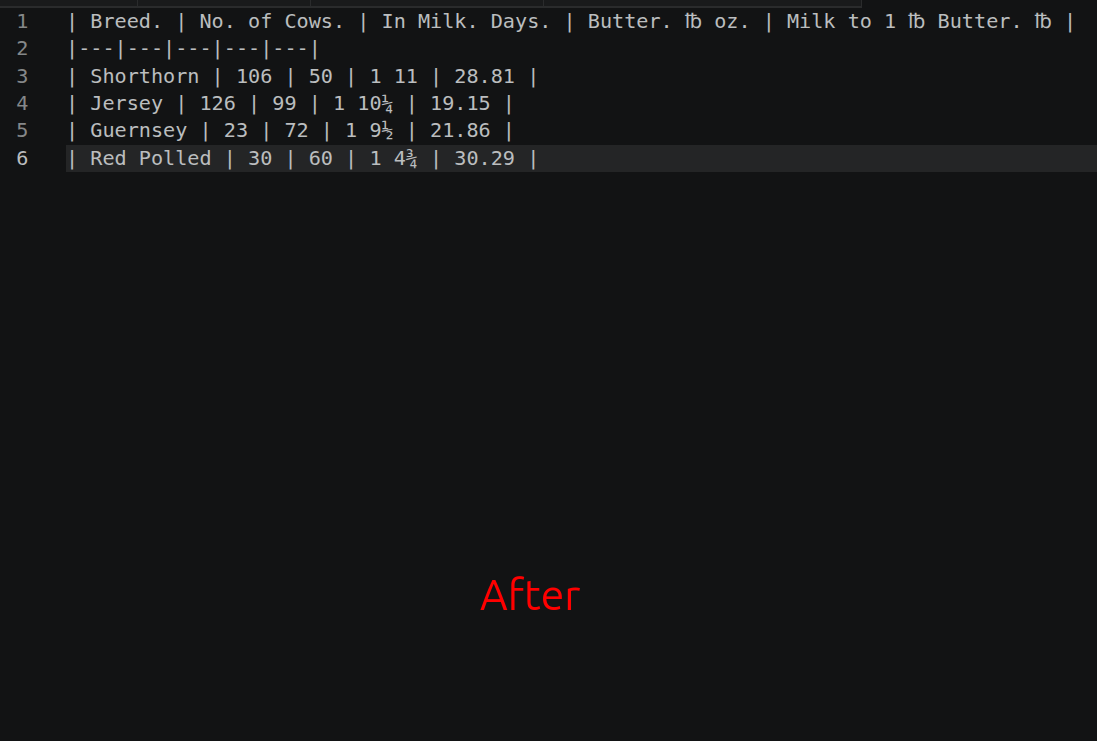
And then there were the tables... When a table was a clean <tr>/<td> grid, I could reconstruct it into Markdown deterministically. I could expand the colspan/rowspan reliably. Chemistry survives this reconstruction intact. Here's one from Accumulator:
| PbO_2 + 2H_2 SO_4 + Pb | = 2PbSO_4 + 2H_2 O |The path is exact, no paraphrasing, no dropped digits or symbols. It's free as in I didn't need to use precious GPU time.
Rabbit hole: once upon a time CPU time was precious, wasn't it? Maybe in the future we are GPU-rich and quantum time is precious?
Emerging from the rabbit hole: Every row the determistic scripting processed for me is one I don't need to wonder if it's done correctly or not. That's the whoel thing, don't spend expensive GPU time (Open-weights LLM) on a problem that can be solved with determinstic scripting.
Second rule - inferece is the fallback for when code cannot win.
The tables above I described were the best cases. It degenerates from there. Tables that defeat parsers because there are apparently no rules and people just type whatever they feel like to make a table of data look like a table of data. blah.
- MathML cells will extract to raw
\displaystyleLaTex mess. - Ditto templates are
{{{1}}}placeholders which mean "same as above" - Columns represented as one cell, like one
<td>with 258<br>tags. There is a mortality table inside of (Annuity) where all the ages between 10 and 96 are collapsed into a big single mushy.
No regex in the world will un-mush that mushy table reliably without breaking other stuff in the process. But an open-weights LLM can, and trivially.
So what was the pathway? Classify every table. Numeric density, the MathML density, column consistency, and others. I would parse the ones that could be reliably parsed, and would call inference for those that I could not reliably parse. Because some of these tables were massive, I didn't trust the sparse-activated Qwen3.6-35B-A3B for this task, and went with the dense qwen3.6-27B model.
The LLM is able to rebuild the mess into a clean Markdown table. The takeaway that I'm really trying to impress upon you though is that the LLM is the fallback, not the primary. The LLM is the tool I bring in only when the cheaper deterministic CPU attempts cannot reliably reconstruct the tables into Markdown.
Rule 3 - always verify LLM output.
This is the part that probably a lot of people skip, because the output they spot check looks soo good. But we can check it, here's some approaches.
- Verify the output is an actual markdown table with a header, separators, rows, etc.
- check for raw LaTeX that maybe the model leaked out during reconstruction.
The strongest part of verification, if you need it: Extract the multiset of numbers from the source HTML as well as from the model's output and compare them. if a digit is dropped or inverted then you know it'd bad. The rule to follow throughout is the same - check the outputs.
Fourth rule - Escape Hatches
Probably the inference pros out there know this well, and nobody else does. So, LLMs are trained to be obedient. Yes they have refusal training and unanserable question training that helps them to avoid doing that which is literally impossible, but these aren't perfect mechanisms. When the shape of a question or task isn't represented well in an LLM's refusal/avoidance training data, it falls through to obedience. i.e. the model is going to answer, no matter if it's unanswerable or not. It'll hallucinate. Frontier models are increasingly less likely to hallucinate but it still happens. Open-weights models are also improving but overall they are further behind the frontier models and halucinate more frequently. It all comes down to the obedience fall-through.
So when a model is trained to be obedient and the shape of your question or task doesn't match negation/refusal patterns, the model will default to being obedient. So how to avoid halucinations when this happens? You put an escape hatch into your instructions.
If the model cannot faithfully do the job, ask it to emit this:
#ESCAPE-HATCH
#REASON: <one short sentence>You can parse that out, record it into a log, and drop the table from the final result. The instruction to the LLM is basically "If this isn't really a data table or it's too corrupted or ambiguous to reconstruct, just say so and don't guess"
Open-weights models use this option. Reliably. It's actually pretty amazing. Here's two real escape hatch usages from qwen3.6-27B
Cosmati - escape-hatch: The HTML represents a genealogical tree diagram rather than a tabular dataset or mathematical formula.
Abyssinia - escape-hatch: a genealogical chart using empty divs for graphical connectors, not a tabular data grid.Cosmati is a Roman family of medieval marble workers and the table is a literal family tree. The relationships of individuals are from the table's visual layout using empty connector cells. Abyssinia's table does the same thing. It's not even text, just cells. To linearize this, the model would have to guess at who decended from whom and the model correctly refused by using the escape hatch. Yes I lost a table but that's better than training my new model on garbage ambiguity that is guessed at.
This can be contrasted with the Binomial article. In that a table is used to hold equations and make them display somewhat like an equation. For those, the model can actually see the whole expression so instead of using the excape hatch it can correctly render the equation without the table structure like this:
(x + a)^n = x^n + n a x^{n-1} + [n(n-1)/1·2] a^2 x^{n-2} + ... + a^n
This is from the same system. Deterministic code says "I can't unmush this, don't know what it is" -> pass it to inference -> Model says "Oh, that's math" and returns the cleaned up equation, while also flagging it as an #EQUATION for deterministic checking (always check) where possible.
Duct-tape and bubble gum
There's some things that didn't make it into the nice highlights I've listed. Notable stuff:
- one malformed table is dropped individually whiel the rest of the article structure and it's precious prose is preserved.
- Check that the infernece server (vLLM in this case) is alive before using it. If it's not, throw a big loud error and exit, don't just silently fail.
- Anything that fails verification or times out is dropped from the finalized article and the item dropped is always logged with a reason for why it was dropped. This gives you a ledger of what didn't make it into your corpora.
Why I love this
In June of 2026 it's easy to just throw everything at a big powerful open-weights model and let it chew through everything in it's path. But that's GPU expensive, and takes a lot of time that I don't want to spend. 37,000 inference calls is something to avoid. And worse, the longer the task for these open-weights models, the more likely they are to screw it up. So disecting all of these articles and parsing out everything you can deterministically is the way to go. Its faster with wall-clock time and more reliable. In addition, by handling most content with deterministic scripting, you shrink the individual bodies of work that you actually do need an LLM's help for, which makes the LLM more reliable due to the smaller task. And of course, always verify - programatically. Don't use an LLM to verify an LLM when you can deterministically script this.
Citations (if you can call them that)
All of the examples I mentioned here are real articles from the actual 1911 Encyclopaedia Britannica on the English Wikisource. You can click through on any of the below to see the exact mess I described for yourself.