Automating AI Quality Checks: A Self-Improving Model Loop
For a long time, I've been building a custom language model that knows World War II content and nothing else. My latest attempts are in the 1-Billion-Parameter range with 32,000 token context. I've built an agentic harness that probes my model using a larger smarter teacher model to find as many mistakes and problems as possible, automatically. The harness writes problem reports which I will use to create targeted synthetic data to close those gaps. This is a personal project using personal resources and personal time.
The video below shows the walkthrough of the technology and the components all running together.
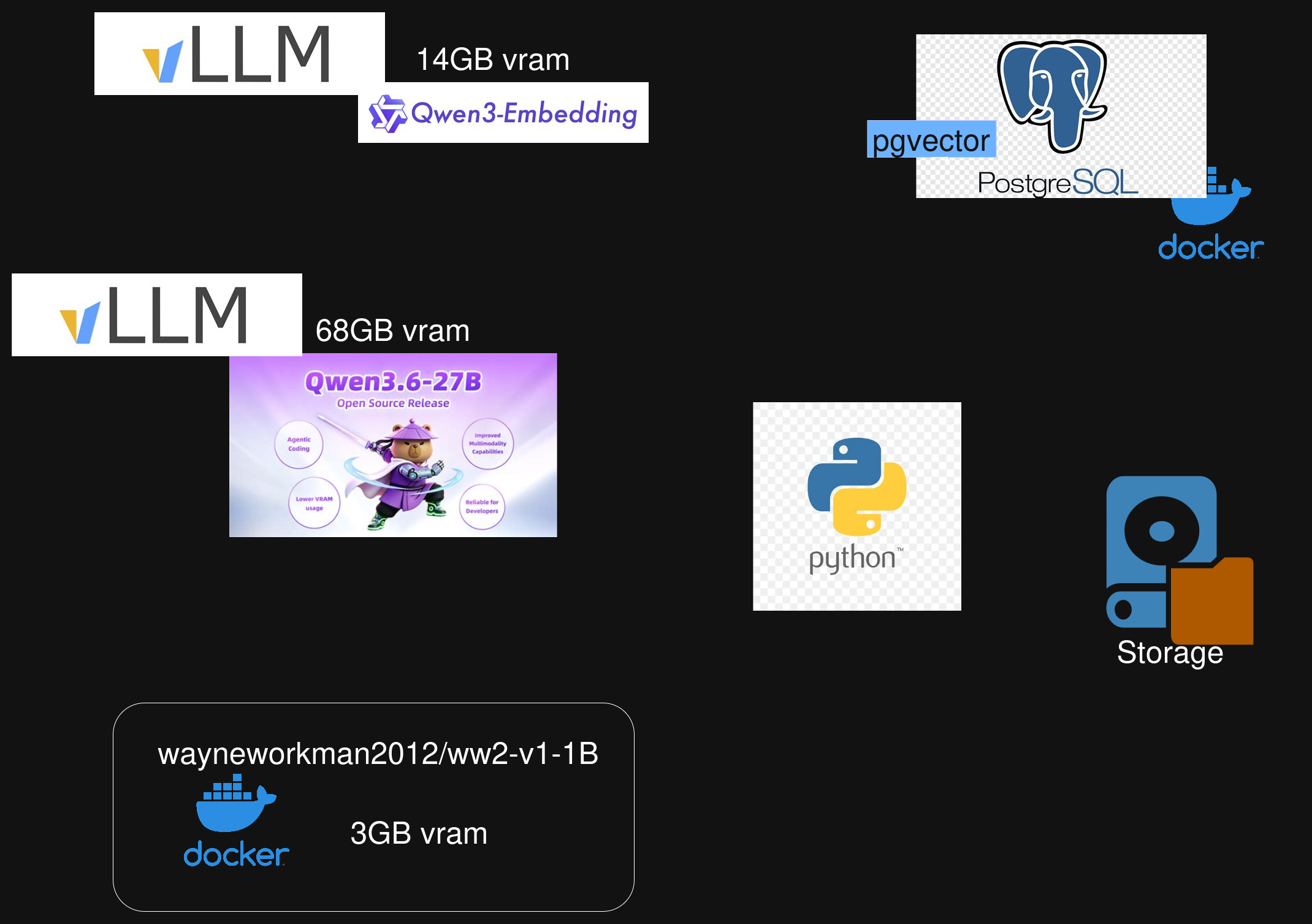
Python orchestrates an open-weights judge LLM that runs on vLLM, qwen/qwen3.6-27B in native precision in this case, using Qwen3-4B embeddings and pgvector store in Postgres, and the student model (my ww2 model) in its own container with an OpenAI compatible API in front of it.
The Easy Part
Training is the easy part. To "train" a language model you need money and time. The more of each, the better your training will go. You configure the training pipeline, adjust your hyper parameters, and you're off to the races. A lot of adjusting happens with the hyperparameters but to be honest this is the really fun part and most of the time you're just watching the metrics, watching the validation scores climb, watching the loss drop, keeping an eye on your gradient norm clipping percentage and the weight distribution of the model. Anxious waiting and watching. Tweaking. Failing and enthusiastically starting the run over. This is absolutely a blast, but its the easy part.
The Hard Part
The hard part is the data. Your training corpus will have problems, flaws. Even if every assistant response is perfect - you may have balance problems in your training materials. too many "No that's false" and too many "No that's incorrect" assistant replies will result in the assistant calling true things false, for example. Been there, done that. Also diversity of request shapes, diversity of response shapes. Being able to answer an oblique question versus knowing when to ask for clarification. This is all... really hard to get right in the data. I've been working on my WWII corpus since December, and conceptually since before even then. I'm still improving the corpus, I'm still balancing it.
The dataset is on HuggingFace if you want to take a look: huggingface.co/datasets/wayneworkman2012/ww2-synthetic-corpus
That dataset is currently 23.8 million training records. I cannot read all of that and I don't want to spend another 7 months checking every line of it with an LLM either. I spot check it, yes, extensively. Obsessively even. But that's not enough, there's too much. Plus there's the shapes and balances problems that you don't see until you get to scale and training time.
Making the Hard Part Easier
SO, how do you find these problems with your data? You don't look at the data. Basically you produce a model trained on the data, and then you quiz the model. The language model is how you speak to the data, how you ask it questions. And you automate that. Which is what I did.
I created a python based agentic harness that basically puts qwen3.6-27B in the driver seat. Qwen gets to prompt my model and ask it questions, then check my model's responses using RAG to see if the responses are correct or not. For all the problems that Qwen observes, it wrties out a problem report. And the idea is with enough problem reports, I can use those to generate targeted synthetic data for exactly the weak spots in my dataset.
The Loop
The loop starts with a judge call. "Here's your topic, here's your tools, find issues with the model and write what you find" ... There's more to it than that, but this is just a high level blog.
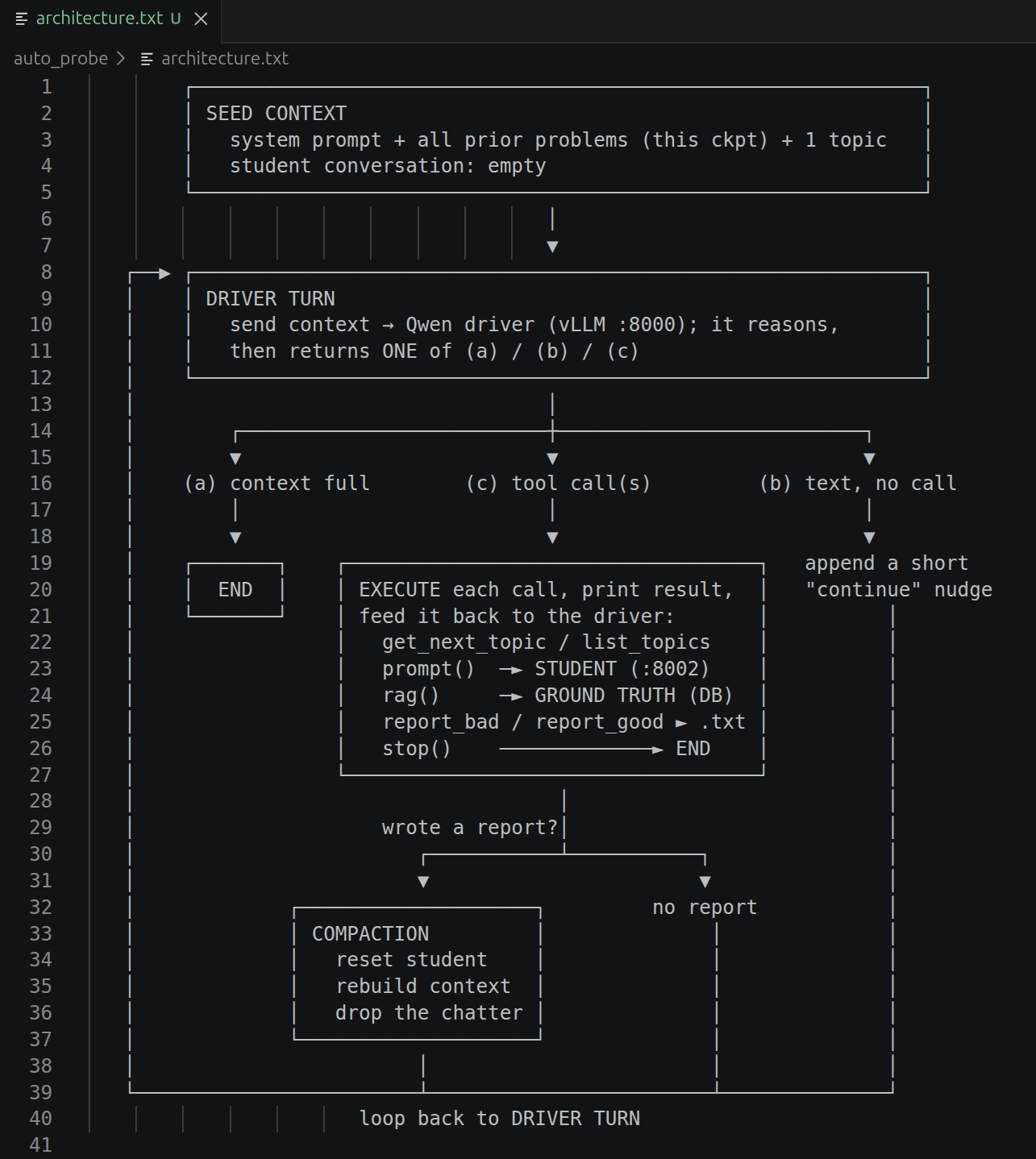
SO Qwen prompts my model and gets a reply. The reply often has facts that my model will volunteer (because it's trained to be helpful). Qwen then uses it's descretion to run those facts and other things through RAG (previously generated with llm + qwen3 embeddings and stored with pgvector /w postgresql). If the content is wrong, qwen may decide to probe my model some more to understand the nature of the problem, to see if maybe a different phrasing results in a different output or the same output, it might ask adjacent questions. Once Qwen understands the nature of the problem, it writes a problem report.
Then the harness auto-compacts the Qwen context. We start over. All problem reports are loaded into the context - but not the RAG back and forth. Not the model back and forth. Not Qwen's thinking-out-loud reasoning. None of that. It's a clean context saying "Here's the previous problem reports, here are your tools, get to it". and Qwen does, it goes again through the loop and produces another problem report. Or a good report showing where my model is strong.
And this continues until the context is full. Filling the context takes a very long time due to the auto-compaction that the harness uses.
The output is not a score
Validation testing, yeah that is very important. Testing on both seen and unseen data, this is the approach that every tutorial will tell you about. It's what any frontier model will tell you to do. It's what I've been doing. And it's not enough.
Today we have at our disposal incredibly intelligent and competent open-weights models that can follow instructions extremely well. The mid-size range is the economical sweet spot - Qwen3.5 / 3.6 and Gemma 4. Qwen3.6-27B is my current favorite for multiple reasons - higher benchmarks as well as a smaller vram footprint which is important when you're running all these things in native precision to get the best results possible. Gemma 4 would be the second choice, though the benchmarks are slightly lower and the 31B dense model needs more vram and runs a bit slower. Trade-offs... use what is best for your workflow.
The output though, these problem reports that Qwen is writing for me, they are going far beyond validation testing. Validation testing gives you a score, and that's important. These problem reports don't give a score, they give you ... exactly the areas where your data is weak. And your job is to take those reports and create synthetic data to plug those gaps. This is gold. Validation testing gives you this tiny glimpse into your model's data problems and training progress... whereas this agentic flow is a different animal - attacking your model's weaknesses, triangulating the problem with the active intelligence of a bigger stronger model, and producing exactly the weak areas for you to work on.
What It Is Not
This is a dense topic, and maybe I'm not being as clear as I could be. So it's important to say what this is not doing. It's not creating new knowledge out of thin air. The approach is grounded. A lot of work (from months ago) went into extracting all knowledge features from the base 301 articles, and work was put into vectorizing all those with an embedding model and storing the vectors and references into a DB. All the knowledge is in the training corpus. We are using that grounded knowledge and semantic similarity to ground Qwen so that Qwen doesn't make stuff up. Grounding is the key it seems, the master key for getting high-end performance from open-weights models. And it's working.
This Approach Scales
While the domain I'm learning and experimenting within is WWII, this approach can apply to any domain. It's generalizable. Embed your knowledge, build a test harness, unleash the LLM of your choosing to work within that harness to find the weaknesses of your LLM - which actually is exposing the weaknesses of the data you trained the LLM on.
The Shift
For most of software history, quality was something a human determined. For perhaps the first time ever, we can now build the tooling and harnesses to allow AI to evaluate AI and drive higher quality. This doesn't remove people from the loop, it promotes people. I'm no longer the grunt doing quality checking. I'm now the operator of a loop that tests thousands of questions, a harness that's producing thousands of problem reports. I'm the boss, and the AI is working for me now. I've been promoted from the trenches to orchestrator. This is a good place to be.